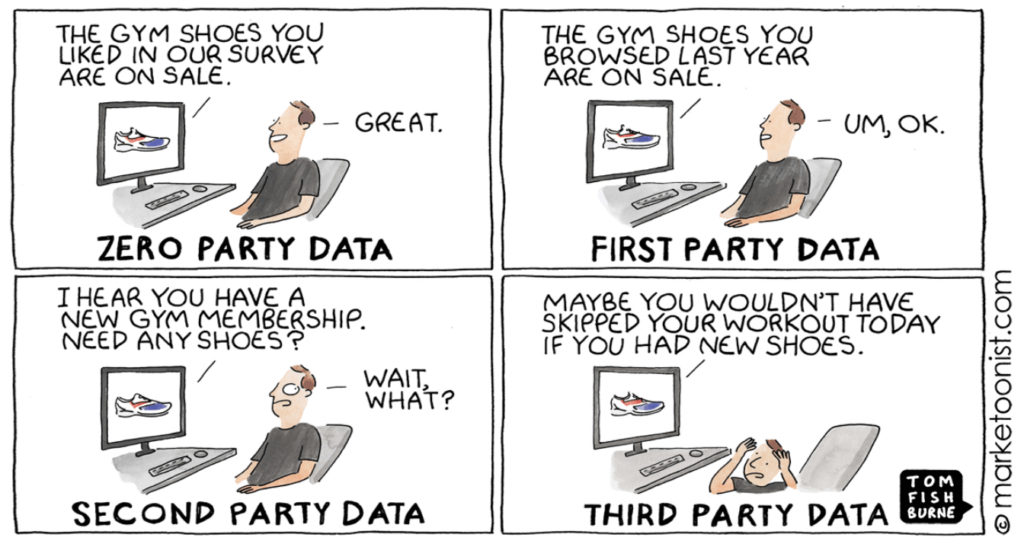
Has this happened to you?
A perfect targeted ad. Or a creepy ad?
Why it is creepy – because big data collected through an array of systems knows everything about you, zeroing in your digital identity. Until 2018, the idea was that more data about users is better, the data that a brand/ publisher could get their hands on, the more likely they’d have high-performing, efficient ad campaigns.
However, data collection was done in a way many users did not understand or know how to opt-out of it. Moreover, when users become aware of third-party sharing and also of firms making inferences about us, they feel intruded upon. This progression of events created a straight line toward a future of a privacy-centric era where there is no “default on” individual user tracking available in the online ad space.
Adtech has been caught in a tug-of-war between Privacy and Data maximization. Adtech till now has been evolved based on big data available leading to further optimization techniques to improve the efficiency and effectiveness of an ad. Now it’s reinventing the wheel around privacy. The paradox is that users expect personalized experiences. Yet they also detest the attempts by brands/publishers to collect personal data about them to deliver these personalized experiences.
With Apple & Google’s announcement (two biggest mobile OS players) of getting away with device identifiers (GAID and IDFA) with “default on”, the adtech industry is navigating through the biggest problem – user identification. Few big players have slightly evolved user identification systems in place but in silos.
The problem here is – portability.
Privacy and big data have become fundamentally opposing forces. So, how does an industry ensure the perfect targeting with lesser big data in hand? Let’s understand what are the different identity systems we have in place and where the industry is heading.
Different User Identity System
1) Third party cookies/ Device identifier:
Devices set identities on users’ behalf i.e. desktop browser, mobile device ids (GAID/IDFA, etc), and IP / device-based connected TV ids. Earlier, these ids were roughly equivalent to a person as we all had one computer with one browser. But not today. Due to devices fragmentation and the way informed users is behaving on all devices. The problem with this ID system is – these are devices that set identities on users’ behalf, not set by users themselves. Once they became aware of third-party sharing of their personal information along with these ids, they felt intruded upon and raised flags about it.
2) Login Ids:
These are publisher-level login-ids created by users (or created by publishers, approved by users) e.g. email id-based login, apple id, Facebook id, publisher-lever user-id, etc. Publishers can further enrich the user’s data using intelligence related to a user, outside the publisher ecosystem. This is trusted and authenticated data by users and brands, as it is 1st party data, owned by the publisher, to be used inside the walled garden of the publisher ecosystem. There is a great possibility of growth as 1st party data eventually is user-approved and can further be enhanced. The only problem is the portability of one publisher id system to another ecosystem. Users are creating different ids with different emails on different avenues, hence, the walled garden approach is limited to its own user growth only, to succeed in the market. It’s more of a competitive scenario, rather than co-operation-based. Many publishers are stitching 3rd party cookies with 1st party data – it makes sense to solve shorter-term business problems though. Amazon ID system (Prime membership) so far has been the most successful id system in this case as it connects the user’s online and offline intelligence under the same identifier and is able to target precisely. E.g. family members might be using the same Prime id by Amazon has device-ids, cookies, persona ids – that can identify and map the behavior and target accordingly.
3) Third party Login Ids:
Publishers use 3rd party login id system, to reduce the friction of user sign-up e.g. login via Facebook, Google, Truecaller id system, etc. Publishers also get additional user intelligence coming along with 3rd party login system. Publishers can further enrich the users’ data using their own data collection activities further. Problem is that publishers are dependent on the 3rd party id system, its security rules, and clauses – which can be changed anytime in the future, hence no control.
4) Universal ID system:
Thirty party players are realizing the issues in the above-mentioned ID system i.e. cookies/device ids and publisher-based ID system. And few of them came up with a universal ID system e.g. UID 2.0, initiated by The Trade Desk, which is an ID system based on an anonymized email id or phone number, that can be shared amongst the partners. This ID system is getting popular ever since data regulation laws took birth (GDPR, CCPA, etc). UID 2.0 has its advantages – Anonymization, Privacy and Control for users, Transparency, Better interoperability).
Problem with this identifier system:
a) Non-logged-in users cannot be targeted.
b) Whose holds the keys? – Ideally, it should be end-user but even 3rd party acting as an independent operator (Prebid in case of UID 2.0) is not going to solve the central problem – user’s are not taking control of their own data. The major concern is – authoritarian and centralization approach.
5) Identifier-less system (No user id):
What if we target not users based on their behavior (action and activities), but not based on user id? Google Floc is one such type of system to target users without exposing the individual user details, but by grouping people with similar interests together. In an ideal world, it’s a win-win scenario for users and brands but practically, there are some roadblocks. a) Attribution is difficult, b) it is not a replacement of ID system, hence inter-operability is still an issue c) browser fingerprinting leads a way to gather users intelligence.
So what’s the direction in privacy-centric era?
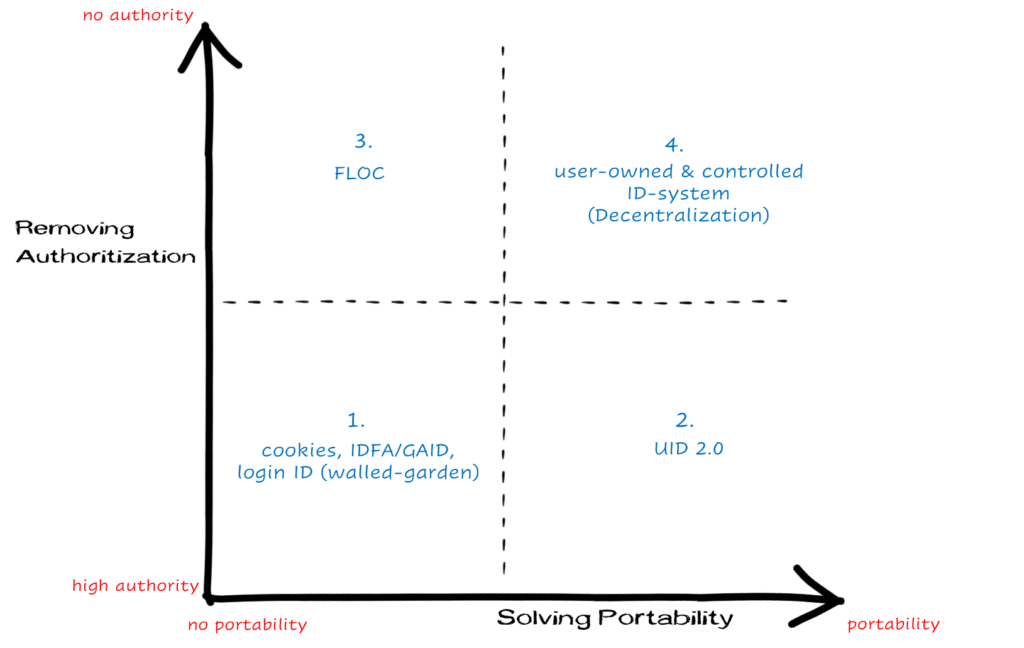
I have created a 2×2 matrix above to understand all the existing models and potential solutions.
On X-axis, we are trying to solve portability i.e. interoperability of different ID systems. On Y-axis, we are trying to remove authorization i.e. end-users should own and control their data, no 3rd party should be taking ownership and controlling users’ data. Let’s understand each quadrant:
Quadrant 1: Cookies, IDFA/ GAID, publisher ID system (walled garden):
Very high authority with publishers or networks, no portability. This is the existing system, still widely used by many partners, but going to be obsolete soon. Users, brands, and publishers have realized the problems and regulatory bodies have started putting laws in place.
Quadrant 2: Universal ID system (UID):
Although it is solving portability problem but still high authority i.e. data owned by 3rd party players (despite we have independent operators and administrators) but users can’t control their data sharing.
Quadrant 3: Identifier-less System:
This is solving data-control problem by not-at-all exposing users identifiers i.e. users have no issues as they are unknown to other parties as individuals, but interoperability is still an issue and one group’s (cohort) behavior might be different at another’s, due to change in context. Plus, in open-web – users still need to enter as an individual to take certain actions.
Quadrant 4: User-owned and user-controlled ID-system:
This is a dream come true – where users hold the keys and take charge of with whom they want to share their data. No central authority and great portability. Web 3.0 conceptually gives birth to this ID system (e.g. wallet id) which is open, trust-less, permission-less, and completely based on decentralization. Everyone can participate without authorization from governing body.
Rather than being obsessed with zeroing humans’ digital identity, we should be working in collaboration with users themselves. And the study shows that if users already trust the platform where users know which of their data is used to show the ads, they might even be more likely to click and buy. Moreover, with the combination of the marketplace, blockchain, and AI, audience targeting can be further improved. Check this<link> story to read more on this.
The direction eventually is to make users’ data be shared more transparent, contextually appropriate and offers a fair value exchange. User should / would “intentionally” and “proactively” shares what he’s interested in and the personalized experience is directly based on what he shares.
Web3.0 vs Web2.0 (w.r.t ID system only)
Let’s understand the difference between web3.0 and web2.0 w.r.t user identity system only. Web2.0 model (or “web as a model”) relies on user participation to create fresh content and profile data. The internet has become a massive app store, dominated by centralized apps from Google, Facebook, and Amazon, where everyone is trying to build an audience, collect data and monetize that data through targeted advertising. The central theme is – the centralization and exploitation of data and the use of it without users’ meaningful consent.
Web3.0 – where no permission is needed from a central authority to post anything and there is no central controlling node. Technologies like distributed ledgers and blockchain will allow for data decentralization and create a transparent and secure environment – users will be able to rightfully own their data.
References:
marketoonist.com/2021/07/zeropartydata.html (photo)




 Swipe for more stories
Swipe for more stories
Comments